This is what i've managed up to now:
I've listed all the netcdf/cmip files under
/g/data2/ua6_jxa900/DKRZ/
and
/g/data2/ua6_jxa900/LLNL
simply using this script

I'm doing the same currently for the BADC directory but it's waiting in the queue
Then I've used my old search_CMIP5_replica.py script to extract only the ensembles, that reduced the lines to something manageable.
Finally I'm creating a sqlite database to list them, the schema is
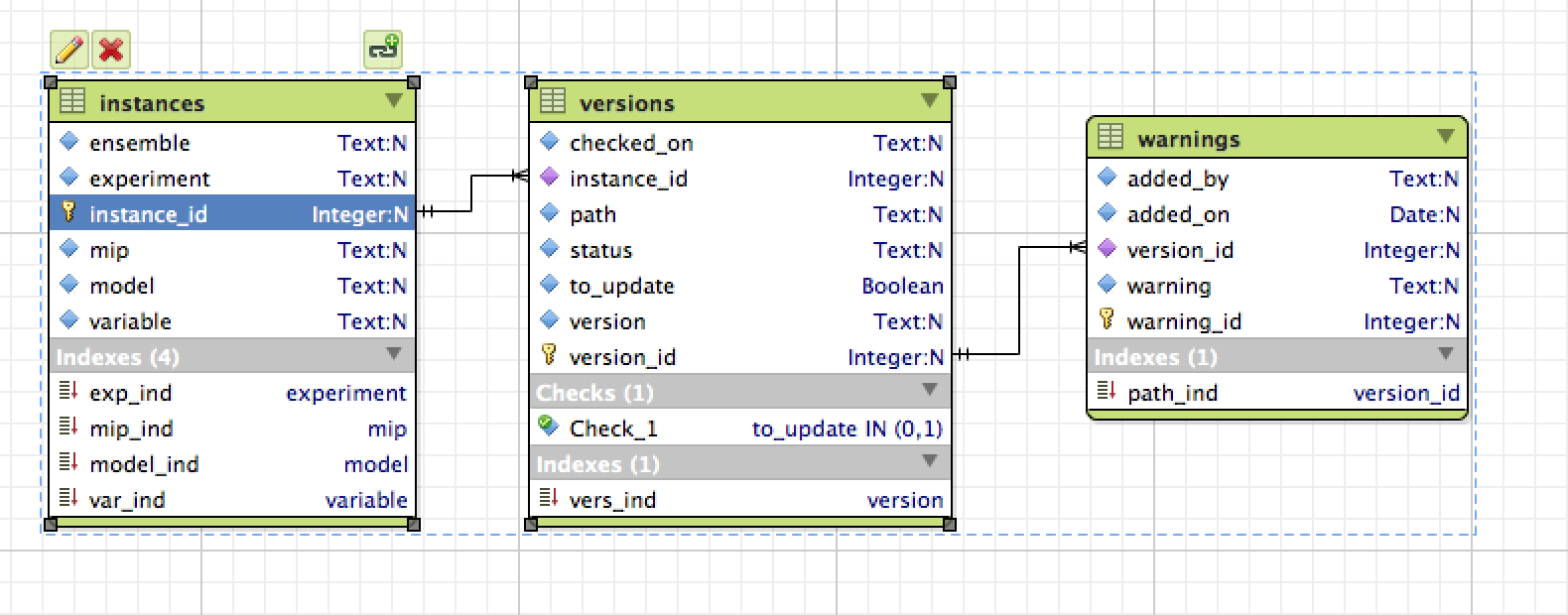
This is the same schema I'm using for the data in unofficial, I've got python script to update the version information and to add user warnings.
I will add them to my CMIP-utils repo, but probably on Monday once I checked them properly.
As "latest" I mean not the latest on raijin, but the latest published, which can't be determined yet until the data is back online, the date checked_on refers to when a "latest/noreplica" search on ESGF was last done and the files checksums compared to what available on raijin.
Both databases are in
/g/data1/ua6/unofficial-ESG-replica/tmp/tree/
bulk_test.db
new_CMIP5_test.db
Unfortunately, I forgot I was cutting a bit of the path that was working fine when everything was coming from unofficial and it's an issue instead for the bulk data, so the current database doesn't have the directory roots, I'm re-running it now. It's relatively fast, but it'll be waiting int he queue for a while. Also the versions at elast for LLNL data don't mean anything out of a local context. So something still needs to be done to compare them to what we have already to determine if they are more or less recent, but also their version number.
I'll be looking into this later working only on subsets I'm interested into, and dd the info to the database. But you might have a better more systematic way to solve this.
Scott as create a python module using SQLalchemy to extract the info ARCCSSive this is a work in progress, in fact I've just added some functionality to check warnings, but hasn't been merged yet. Any feedback appreciated.