We are introducing two main components of AI/ML techniques: the software frameworks; and the models:
AI/ML software frameworks
The following section introduces the main HPC AI/ML enabled frameworks.
Tensorflow
Tensorflow is an open-source framework for machine learning, developed by Google. It is an end-to-end machine learning solution with a rich set of APIs. The initial version of TensorFlow was released in 2015. Since then, it has been successfully used in a variety of machine learning tasks including handwritten digit classification, image recognition, object detection, and time series data prediction. Tensorflow is compatible with modern GPU architectures and fully supports distributed model training.
Internally, Tensorflow operates by manipulating dataflow graphs. Developers can define and create data graphs, where each node represents an operation and links represent the data flow among the nodes. Tensorflow has advanced level capabilities to handle and process multi-dimensional data efficiently during training. Once the model is trained, it can be deployed in sceneries including mobile, Edge, and IoT devices.
Fig.1. show the conceptual hierarchy of the Tensorflow framework. At the top, high-level constructs like Keras make it easy to deploy models and load datasets. Tensorflow estimators make it easy to encapsulate training, evaluation, and prediction using pre-built or pre-trained models. In the next layer, we have functions like tf.layers, tf.losses, tf. metrics, etc. that are required if you want to define and build your own models. In most cases, researchers want to use this layer to define new models.
The last two layers are the Tensorflow low-level API and Hardware layers. Low-level API has C/C++ language bindings for stricter hardware control. The same Tensorflow model can run on either conventional CPUs, high-performance GPUs, or Google's proprietary tensor processing units (TPUs) with a minimum amount of code change. A machine learning developer or researcher rarely needs to worry about low-level operations, as all of these can be achieved by the high-level APIs above.

Figure 1. TensorFlow conceptual hierarchy. (source: https://developers.google.com/static/machine-learning/crash-course/images/TFHierarchyNew.svg)
Pytorch
Pytorch is another open-source machine learning library based on an older machine learning library called Torch. The framework was reworked and rewritten in Python to keep pace with modern machine learning demands.
Pytorch was developed by Meta AI (formally Facebook) in 2017 and quickly became popular due to numerous machine learning features and simplicity of use. Pytorch coding syntax closely follows that of Python, thus, anyone familiar with Python will find this framework easy to work with. Pytorch introduces some extra modules for distributed deep learning, for example, the torch.distributed module can be used to perform model optimisation on multiple GPUs.
Figure 2 gives a high-level view of the PyTorch architecture. A user has the option to define a model or use a predefined model. A researcher can define new models using a high-level API. Pytorch also has predefined models that can be used out of the box for training and inference. Similarly, one can prepare one's own data or use the Pytorch data loader class to download data from the Pytorch archive. Thus, PyTorch gives a lot of flexibility to users.
Figure 2. Pytorch Architecture
Horovod
Horovod is a deep learning framework initially developed by Uber and has since been used by multiple organisations for distributed training. The main advantage is to be able to run distributed deep learning operations in just a single command. Once the script is written for Horovod, the same script can be used on a single-GPU, multiples GPU or across multiple nodes, and doesn't have to explicitly define the number of GPUs or nodes. This makes it much easier for data scientists to experiment with varying numbers of GPUs.
Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. Horovod uses the NVIDIA Collective Communications Library (NCCL) for inter-GPU communication and Gloo for inter-node communication. These methods allow Horovod to efficiently distribute and aggregate model parameters among multi-node GPUs.
Horovod makes distributed deep learning faster using ring-allreduce communication protocol for workers. This protocol allows each training process to exchange partial gradient data with peers using dual channels. Using this clever implementation for data exchange, Horovod fully utilises the dual communication channel between GPUs. Workers do not wait for complete gradient transmission from a process; instead dual-channel mutual communication is performed in small batches, which makes ring-allreduce communication protocol to take full advantage of inter-GPU high-speed connections.
The following diagram gives a conceptual view of how the ring-allreduce communication protocol works.
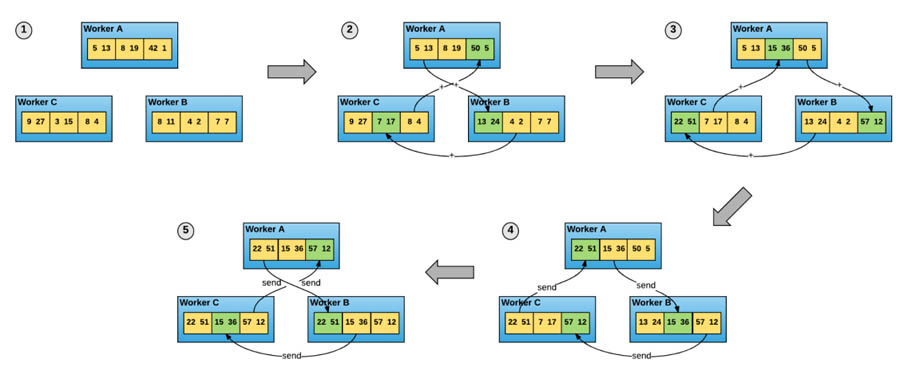
Figure 3. The conceptual view of the ring-allreduce algorithm (source: https://arxiv.org/pdf/1802.05799.pdf).
Next, we are going to introduce the Residual network for multi-GPU and multi-node training. It is a well-known model for large-scale object detection.
AI/ML models
Resnet-101 model
Resnet-101 is a particular implementation of the more general Resnet architecture. Fig. 4. shows an example of a plain and residual neural network. The basic concepts are explained with a 34-layer residual network. The Resnet-101 has a similar structure; however, with more layers.
In Fig.4 below, VGG-19 and 34-layer convolutional networks are shown side by side for comparison. The plain 34-layer network is based on the VGG network, the only difference is that the 34-layer network uses more layers of each type present in the VGG network. The introduction of those extra layers introduces the problem of vanishing gradient, where the gradient in the successive layers becomes so small that they become unusable.
Next to the plain network, a residual network is also shown. One can easily see that the only difference between the 34-layer plain network and the residual network is the residual blocks. Each residual block bypasses a weighted layer and combines the output of a weighted layer directly with the original input. It can be seen in the residual network, that each two convolution layers are using identity links to bypass a layer. This alleviates the problem of vanishing gradient and makes it possible to add many more layers to the deep neural networks. All residual networks follow this same basic principle.
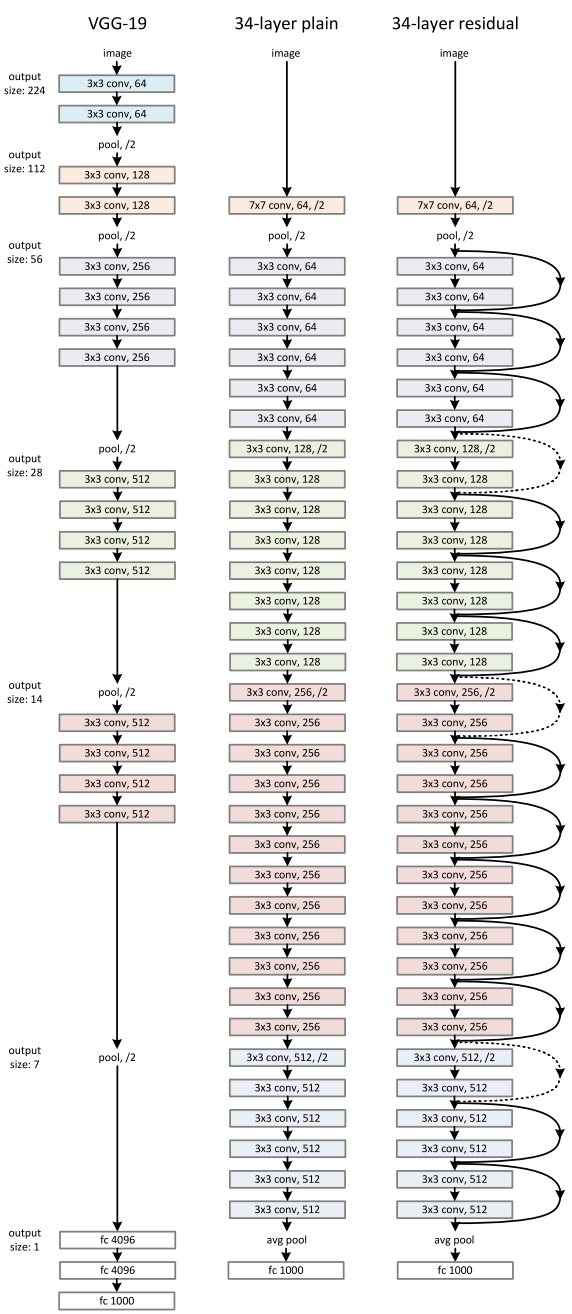
Figure 4. Three network architectures. Left: VGG-19 model, middle: A plain 34 parameter network, right: A 34 parameter Residual network. (source: https://arxiv.org/pdf/1512.03385.pdf)
Further reading:
The ResNet-101 model can be trained using the ImageNet dataset. Interested readers can find out more about the ImageNet dataset in the following links: https://opus.nci.org.au/x/YYEYCg, https://opus.nci.org.au/x/KIDSCQ.
Code examples of distributed training using the ResNet-101 model can be found here: https://opus.nci.org.au/x/pIEYCg, https://opus.nci.org.au/x/q4EYCg