Contents
The Sandy Bridge CPUs in Raijin compute nodes and Haswell CPUs in the GPU nodes provide 256-bit vector registers and AVX/AVX2 (Advanced Vector Extensions) instruction sets. The Xeon Phi CPUs in the KNL nodes provide 512-bit vector registers and AVX-512 instruction sets. To get the most performance out of these processors, users need to take advantage of these strengths and try to improve the usage of vectorization instructions in their code. This document provides a guideline on how to get vectorization information and improve code vectorization.
Get Vectorization Information
There are various ways to get information regarding how a code is vectorized. The following information is for Intel compilers. For GCC compilers please refer to the corresponding man page or documentation.
1.The compiler option '-S' can be used to generate assembly code instead of binary. In the assembly code, SSE vector instructions generally operate on xmm registers, AVX and AVX2 on ymm registers, and AVX512 on zmm registers. AVX, AVX2, and AVX512 instructions are prefixed with 'v'.
Example of compiling a C++ program to generate assembly code instead of binary code:
icpc -S -o vec_add.s vec_add.cc
Example of generated vectorized assembly code:
vldmxcsr 64(%rsp) vaddpd (%rsp), %zmm0, %zmm1 vmovupd %zmm1, (%rsp)
2.Compiler option '-qopt-report=5' can be used to generate an optimization report, which contains vectorization information. To generate report for vectorization only, use "-qopt-report -qopt-report-phase=vec".
3.Intel Advisor XE 2016 has a feature called Vectorization Advisor to help analyse existing vectorization, detect "hot" un-vectorized or under-vectorized loops, and provide advices to improve vectorization use.
(For details of how to use Intel Advisor and its Vectorization Advisor, refer to Intel Advisor Tutorial: Add Efficient SIMD Parallelism Using the Vectorization Advisor.)
Intel Advisor provides both command line and GUI tools, called advixe-cl and advixe-gui respectively. To use Intel Advisor to get vectorization information, users can compile and run their code in the following steps:
1) Compile and link Fortran/C/C++ program using corresponding Intel compiler with the vectorization option:
Example:
module load intel-cc/16.0.3.210 icc -g -qopenmp -O2 example.c –o example
Some Intel compiler options are listed below:
| Compiler option | Function |
|---|---|
| -g | Build application with debug information to allow binary-to-source correlation in the reports. |
| -qopenmp | Enable generation of multi-threaded code if OpenMP directives/pragmas exist. |
| -O2 (or higher) | Request compiler optimization. |
| -vec | Enable vectorization if option O2 or higher is in effect (enabled by default). |
| -simd | Enable SIMD directives/pragmas (enabled by default). |
For details of these options refer to man page or documentations of Intel compilers.
2) Submit a PBS job which executes the binary and runs the Intel Advisor command line tool advixe-cl to collect vectorisation information:
Example (PBS scripting part is omitted):
...... module load intel-advisor/2016.1.40.463413 advixe-cl --collect survey --project-dir ./advi ./example
For a 4-process MPI program, collect survey data into the shared ./advi project directory:
...... module load intel-advisor/2016.1.40.463413 mpirun -n 4 advixe-cl --collect survey --project-dir ./advi ./mpi_example_serial
3) Once the job finishes, launch advixe-gui on a login node to visualize the data collected by advixe-cl:
Example:
module load intel-advisor/2016.1.40.463413 advixe-gui &
- Choose “Open Result” tab and then select the .advixeexp file generated by advixe-cli in previous step.
- In the “Summary” part the summary of the report generated by Vectorization Advisor is shown. Vector instruction sets used, vectorization gain/efficiency are shown. Below is a screenshot of of the summary for a code run on a KNL node:

- The Survey Report provides detailed compiler report data and performance data regarding vectorization such as:
- Which loops are vectorized, the location in the source code
- Vectorization issues
- The reason why a loop is not vectorized
- Vector ISA used
- Vectorization efficiency, speedup
- Vector length (# of elements processed in the SIMD instruction)
- Vectorization instructions used
Below is a screenshot of of the Survey Report for a code run on a KNL node:
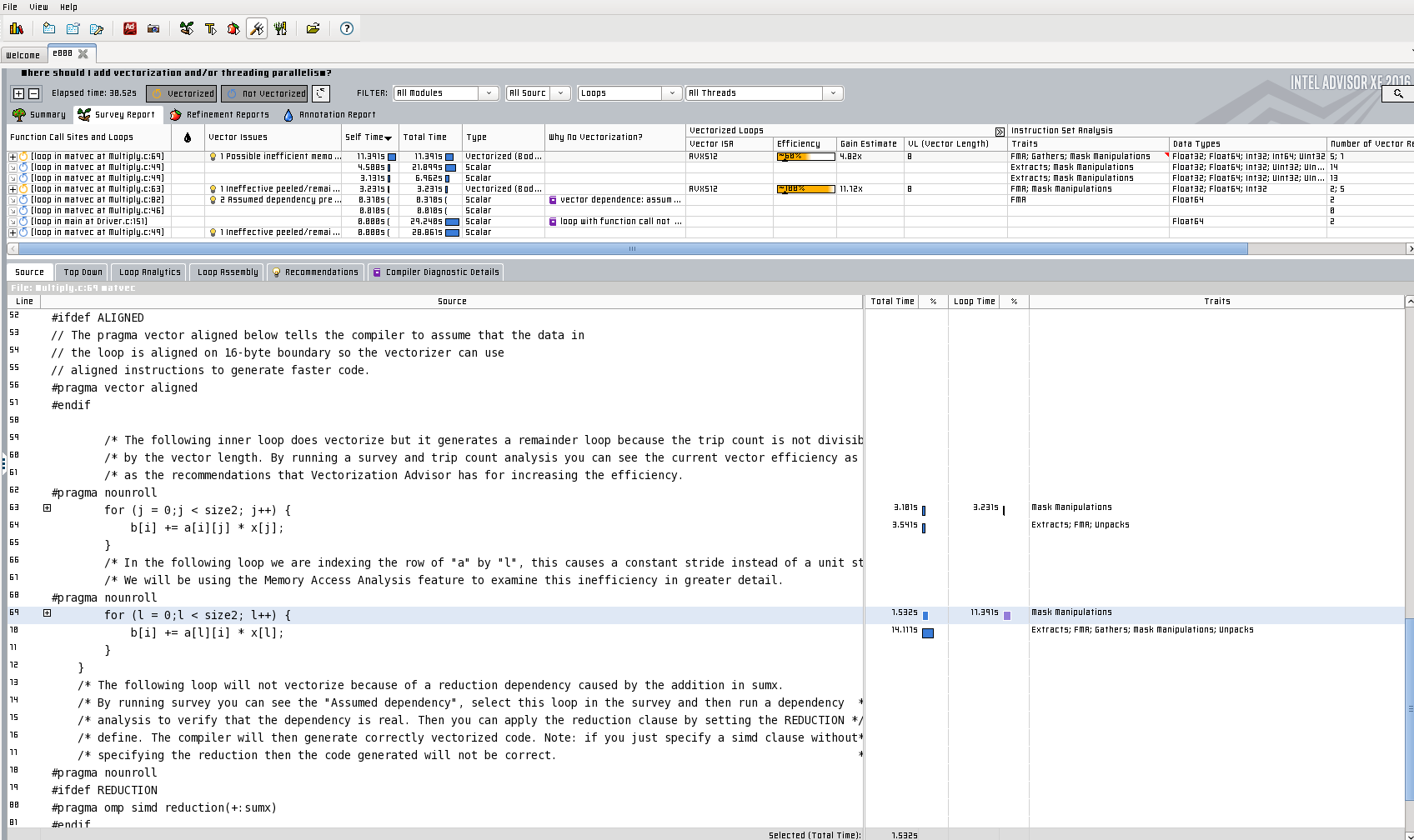
If a loop cannot be vectorized with automatic vectorization, Intel Advisor will provide the reason and advices on how to fix the vectorization issues specific to your code, such as dependency analysis and memory access pattern analysis. Users should follow these advices, modify their source code and give compiler more hints to improve vectorization, by using compiler options or adding directives/pragmas to the source code (explicit vectorization).
Explicit Vectorization
Compiler SIMD directives/pragmas
Users can add compiler SIMD directives/pragmas to the source code to tell the compiler that dependency does not exist, so that the compiler can vectorize the loop when the user re-compiles the modified source code. Such SIMD directives/pragmas include:
#pragma vector always: instruct to vectorize a loop if it is safe to do so #pragma vector align: assert that data within the loop is aligned on 16B boundary #pragma ivdep: instruct the compiler to ignore potential data dependencies #pragma simd: enforce vectorization of a loop
OpenMP directives/pragmas
Users can use OpenMP 4.0 new directives/pragmas for explicit vectorization:
#pragma omp simd: enforce vectorization of a loop #pragma omp declare simd: instruct the compiler to vectorize a function #pragma omp parallel for simd: target same loop for threading and SIMD, with each thread executing SIMD instructions
Compiler options and macros
Users can also use compiler options and macros for explicit vectorizaiton:
-D NOALIAS/-noalias: assert that there is no aliasing of memory references (array addresses or pointers) -D REDUCTION: apply an omp simd directive with a reduction clause -D NOFUNCCALL: remove the function and inline the loop -D ALIGNED/-align: assert that data is aligned on 16B boundary -fargument-noalias: function arguments cannot alias each other
If you are experiencing an error like the following, then use export ADVIXE_MORE_PIN_OPTIONS='-ifeellucky' to set the environment variable ADVIXE_MORE_PIN_OPTIONS (bash):
advixe: Error: [Instrumentation Engine]:
Source/pin/injector_nonmac/auxvector.cpp: CopyAux: 291: unexpected AUX
VEC type 26
advixe: Collection failed.
advixe: Error: The collection was not able to run.
advixe: Error: Data loading failed.
advixe: Error: unknown_fail
SIMD enabled functions
Users can also declare and use SIMD enabled functions. In the example below, function foo is declared as a SIMD enabled function (vector function), so it is vectorized. So is the for loop in which it is called.
__attribute(vector)
float foo(float);
void vfoo(float *restrict a, float *restrict b, int n){
int i;
for (i=0; i<n; i++) { a[i] = foo(b[i]); }
}
float foo(float x) { ... }
Programming Guidelines for Writing Vectorizable Code
- Use simple loops, avoid variant upper iteration limit and data-dependent loop exit conditions
- Write straight-line code: avoid branches, most function calls or if constructs
- Use array notations instead of pointers
- Use unit stride (increment 1 for each iteration) in inner loops
- Use aligned data layout (memory addresses)
- Use structure of arrays instead of arrays of structures
- Use only assignment statements in the innermost loops
- Avoid data dependencies between loop iterations, such as read-after-write, write-after-read, write-after-write
- Avoid indirect addressing
- Avoid mixing vectorizable types in the same loop
- Avoid functions calls in innermost loop, except math library calls
Overview
Content Tools