-
Created by
 Yue Sun, last updated by Rui Yang on Apr 19, 2023
4 minute read
Yue Sun, last updated by Rui Yang on Apr 19, 2023
4 minute read
Motivation
AlphaZero is a deep reinforcement learning model developed by DeepMind that learns to play games. It can improve its performance through self-play. Similar model architectures have been used to discover efficient and provably correct algorithms for the multiplication of arbitrary matrices [AlphaTensor], find principal components analysis solution for d-dimensional data as the Nash Equilibrium of a game [EigenGame], and explore Nash equilibrium of games with many players [ADIDAS] and/or imperfect information [DeepNash].
More broadly, reinforcement learning has been used to solve scientific problems, such as protein folding, drug discovery, and gene expression analysis. In addition, it has been used to develop AI-based models for predicting the behaviour of complex physical systems, such as the motion of stars and galaxies, or the flow of fluids. RL is also being used to develop AI systems that can interact with the physical world, such as robots and autonomous vehicles.
Using this fast implementation of AlphaZero, we demonstrate here how to run deep reinforcement learning model efficiently at scale at NCI.
Usage Example
Load the module "NCI-ai-ml/23.03" to use AlphaZero.jl as shown below.
$ module use /g/data/dk92/apps/Modules/modulefiles/
$ module load NCI-ai-ml/23.03
Loading NCI-ai-ml/23.03
Loading requirement: singularity openmpi/4.1.4
$ julia
_
_ _ _(_)_ | Documentation: https://docs.julialang.org
(_) | (_) (_) |
_ _ _| |_ __ _ | Type "?" for help, "]?" for Pkg help.
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 1.6.7 (2022-07-19)
_/ |\__'_|_|_|\__'_| | Official https://julialang.org/ release
|__/ |
(@v1.6) pkg> st AlphaZero
Status `/opt/julia/environments/v1.6/Project.toml`
[8ed9eb0b] AlphaZero v0.5.4
julia> using AlphaZero
julia>
Run the code in a JupyterLab notebook
- Copy the tested notebook from "/g/data/dk92/notebooks/examples-julia/AlphaZero/alphazero.profile.ipynb" to your own working directory
- Go to ARE site: are.nci.org.au
- Fill out the JupyterLab request form and replace <xy01> with your own project code
- Walltime (hours): 2
- Queue: gpuvolta
- Compute Size: 2gpu
- Project: <xy01>
- Storage: gdata/dk92+scratch/<xy01>
- Click Advanced options and fill in the following fields
- Module directories: /g/data/dk92/apps/Modules/modulefiles/
- Modules: NCI-ai-ml/23.03
- Environment variables: SINGULARITYENV_JULIA_NUM_THREADS=9
- Jobfs size: 200GB
- Launch the session and run the notebook from your own directory
Run the job across multiple nodes in a PBS job
We prepared four training scripts using different ClusterManagers and archived then in "/g/data/dk92/notebooks/examples-julia/AlphaZero/scripts", copy the entire directory to your own project directory to run the training using any of the following configurations.
| script | #GPU | ClusterManager | JULIA_NUM_THREADS | Expected walltime per iteration |
|---|---|---|---|---|
| training.jl | 1 | n.a. | 9 | 40 min |
| SSHManager/ssh.mg.training.jl | 2-4 | LocalManager | 9 | 15 min if using 4 V100 GPUs |
| SSHManager/ssh.mnmg.training.jl | 8 | SSHManager | 9 | 11 min |
| MPIManager/mpi.training.jl | 2-4,8 | MPIManager | 1 | 18 min if using 8 V100 GPUs |
For example, train the connect-four game using 4 V100 GPUs through LocalManager as below.
$ mkdir -p /scratch/$PROJECT/$USER/AlphaZero $ cp -r /g/data/dk92/notebooks/examples-julia/AlphaZero/scripts /scratch/$PROJECT/$USER/AlphaZero $ cd /scratch/$PROJECT/$USER/AlphaZero/scripts $ qsub job.sh
Here is an example to train the connect-four game on 8 GPUs using MPIManager.
#!/bin/bash #PBS -l walltime=5:00:00 #PBS -l ncpus=96 #PBS -l ngpus=8 #PBS -l mem=760GB #PBS -l jobfs=400GB #PBS -l wd #PBS -q gpuvolta #PBS -l storage=gdata/dk92 export GKSwstype=100 module use /g/data/dk92/apps/Modules/modulefiles/ module load NCI-ai-ml/23.03 cat $PBS_NODEFILE | uniq > ./hosts script=$PBS_O_WORKDIR/MPIManager/mpi.training.jl mpirun -np $PBS_NGPUS --map-by ppr:1:NUMA:PE=12 julia $script >& output.$PBS_JOBID
where the Julia training script reads as
#add a writable dir to DEPOT_PATH so that compiled files can be written
tmpenv = mkpath(joinpath("/scratch",ENV["PROJECT"],ENV["USER"],"juliaenv"))
pushfirst!(DEPOT_PATH,tmpenv)
using MPIClusterManagers, Distributed, CUDA
import MPI
MPI.Init()
rank = MPI.Comm_rank(MPI.COMM_WORLD)
size = MPI.Comm_size(MPI.COMM_WORLD)
if rank == 0
@info "total number of ranks is $size"
end
ngpus=parse(Int64,ENV["PBS_NGPUS"])
ngpus_per_node = ngpus/parse(Int64,ENV["PBS_NNODES"])
h = gethostname()
d = Int64(mod(rank,ngpus_per_node))
device!(d)
@info "rank $rank uses GPU $d on $h"
manager = MPIClusterManagers.start_main_loop(MPI_TRANSPORT_ALL)
@info "There are $(nworkers()) workers"
@everywhere using Distributed
@everywhere using AlphaZero
Scripts.train("connect-four";dir="sessions/mpi.connect-four-$(ngpus)v100")
MPIClusterManagers.stop_main_loop(manager)
t=rmprocs(workers())
wait(t)
exit()
If using /g/data/$PROJECT/$USER as the working directory for the job, don't forget to add it to the PBS storage directive in the job submission script job.sh.
Discussion: Efficiency and Scalability
Multiple GPUs
We used the default parameters set by AlphaZero.jl developer to train the game connect-four on 1 V100 GPU, 4 V100 GPUs(single node), and 8 V100 GPUs(two nodes) using both MPIManager and SSHManager and here is the comparison of time spent in self-play phase of the game.
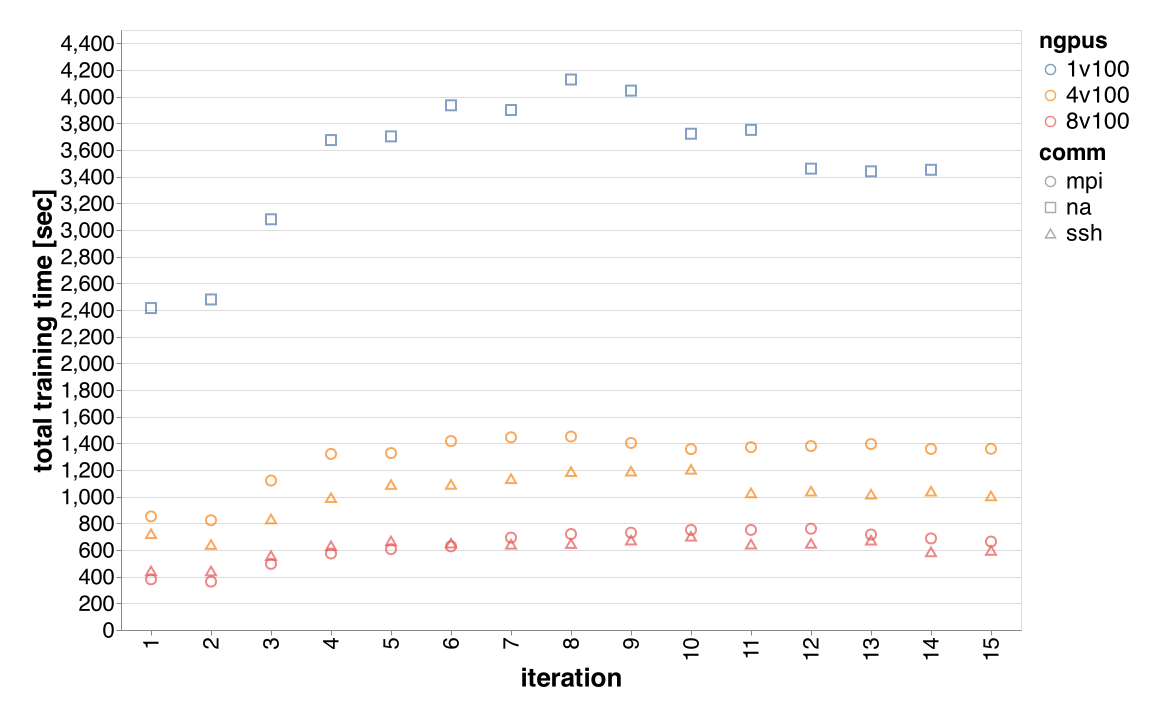
Within a node, SSHManager is faster. Across two nodes, SSHManager performs very similar to MPIManager as the communication case in the self-play phase is very limited.
Note, in the learning phase where more communication is required between workers, SSHManager introduces much higher overhead compared to MPIManager when the training runs across two nodes, and results in 2x overall time spent in the learning phase.
Multiple Threads
By using multiple threads, we are able to increase the GPU utilisation rate from 40% to 70% during the self-play phase. The measurement of time spent in self-play confirms the observation, see below for time spent in self-play using 1, 4, 9 threads when training the game using 4 V100 GPUs. In the learning phase, enabling multiple threads also speed up the run, however, the margin is relatively small compare to the self-play phase, 2x vs 1.28x.
