This is what i've managed up to now:
I've listed all the netcdf/cmip files under
/g/data2/ua6_jxa900/DKRZ/
and
/g/data2/ua6_jxa900/LLNL
simply using this script

I'm doing the same currently for the BADC directory but it's waiting in the queue
Then I've used my old search_CMIP5_replica.py script to extract only the ensembles, that reduced the lines to something manageable.
Finally I'm creating a sqlite database to list them, the schema is
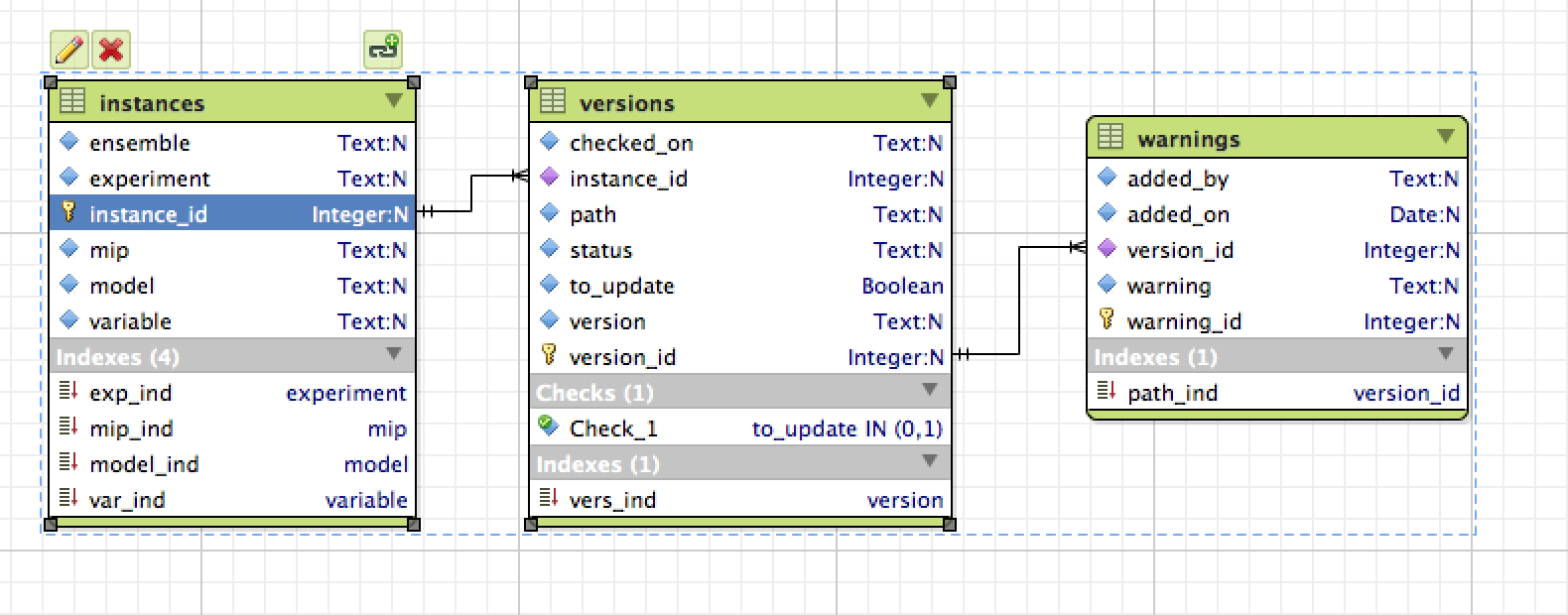
This is the same schema I'm using for the data in unofficial, I've got python script to update the version information and to add user warnings.
I will add them to my CMIP-utils repo, but probably on Monday once I checked them properly.
As "latest" I mean not the latest on raijin, but the latest published, which can't be determined yet until the data is back online, the date checked_on refers to when a "latest/noreplica" search on ESGF was last done and the files checksums compared to what available on raijin.
Both databases are in
/g/data1/ua6/unofficial-ESG-replica/tmp/tree/
bulk_test.db
new_CMIP5_test.db
Unfortunately, I forgot I was cutting a bit of the path that was working fine when everything was coming from unofficial and it's an issue instead for the bulk data, so the current database doesn't have the directory roots, I'm re-running it now. It's relatively fast, but it'll be waiting int he queue for a while. Also the versions at elast for LLNL data don't mean anything out of a local context. So something still needs to be done to compare them to what we have already to determine if they are more or less recent, but also their version number.
I'll be looking into this later working only on subsets I'm interested into, and dd the info to the database. But you might have a better more systematic way to solve this.
Scott as create a python module using SQLalchemy to extract the info ARCCSSive this is a work in progress, in fact I've just added some functionality to check warnings, but hasn't been merged yet. Any feedback appreciated.
I've tried to download some data from pcmdi9 using the scripts created by Lawson. The data transfer went ok, but the md5 checksum fails. Turns out that they are using a different hashing algorithm SHA256, but when executing the wget file at the end of the download still calculates MD5. So the hash ends up being different from the one listed in the same wget script. The original wget script has the correct code which check if the node has passed an md5 or sha256 hash, but Lawson scripts insert a section that calculates md5sum by default.
To be more clear, this is what a new file line looks like in a wget script
'tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc' 'http://aims3.llnl.gov/thredds/fileServer/cmip5_css01_data/cmip5/output1/LASG-CESS/FGOALS-g2/rcp85/3hr/atmos/3hr/r1i1p1/v2/tas/tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc' 'SHA256' '8f67c9f75395212495cbe9138863ba77012f6749457dbed82542b06525391e13'
this what I’m getting by running wget for one file
tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc ...Already downloaded and verified
done
ERROR file 'tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc' MD5 checksum test failed
This is from the modified "trailer-part" of the wget script after the download is completed:
if [ "x8f67c9f75395212495cbe9138863ba77012f6749457dbed82542b06525391e13" != "x" ]
then
newMd5=`md5sum tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc | awk '{print $1}' -`
if [ "${newMd5}" != "8f67c9f75395212495cbe9138863ba77012f6749457dbed82542b06525391e13" ]
then
echo "ERROR file 'tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc' MD5 checksum test failed" >> /home/581/pxp581/cm5-download-errors.log
echo "ERROR file 'tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc' MD5 checksum test failed" 1>&2
exit 99
fi
fi
Changing cm5-download-mod2.sh so that it adds this bit of code after "then" seems to fix it
case $chksum_type in
md5)
newMd5=`md5sum tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc | cut -d ' ' -f1 `;;
sha256)
newMd5=`sha256sum tas_3hr_FGOALS-g2_rcp85_r1i1p1_203901010300-204001010000.nc |cut -d ' ' -f1`;;
esac
So around line 690 of cm5-download-mod2.sh
echo " if [ \"x${md5}\" != \"x\" ]" >> $oFile
echo " then" >> $oFile
echo " case \$chksum_type in" >> $oFile
echo " md5)" >> $oFile
echo " newMd5=\`md5sum ${lfn} | cut -d ' ' -f1\`;;" >> $oFile
echo " sha256)" >> $oFile
echo " newMd5=\`sha256sum ${lfn} | cut -d ' ' -f1\`;;" >> $oFile
echo " esac" >> $oFile
echo " " >> $oFile
echo " if [ \"\${newMd5}\" != \"${md5}\" ]" >> $oFile
echo " then" >> $oFile
.....
Changes in servers' names
My version of the bash scripts now works again fine and can download files, the problem is that some of the servers have changed name and consequently the url in which we relied to identify if the file was already in the tree area. Initially I've modified my scripts to make sure for example that if the server was aims3.llnl.gov the script will also check files in pcmdi3{7/9}.llnl.gov . Then I noticed that dkrz changed server name too and handling all these exceptions it's too messy.
Not to say that PCMDI is not using the proper ensemble version but directories named 1/2/3 etc instead. Since the use of elasticsearch has been momentarily suspended, I'm looking again at using the sqlite database to handle this.
So I'm starting today to adapt my python script to download the search for data, update information on database including new fields for md5 and sha256 checksum and finally download the data if it isn't there.
Clearly adding md5/sha256 info means that we need to have a row for each file and so probably I'll have to split the database in different "experiments" or try to use postgres or mysql. Any suggestion and or comment on this is very welcome.